CLIP: Language-Image Pretraining
What is CLIP?
CLIP (Contrastive Language-Image Pretraining) is a neural network model developed by OpenAI that learns to associate images and text by training on a large dataset of image-text pairs. It bridges vision and language, enabling tasks like image classification, object detection, and text-to-image generation without task-specific training.
How Does CLIP Work?
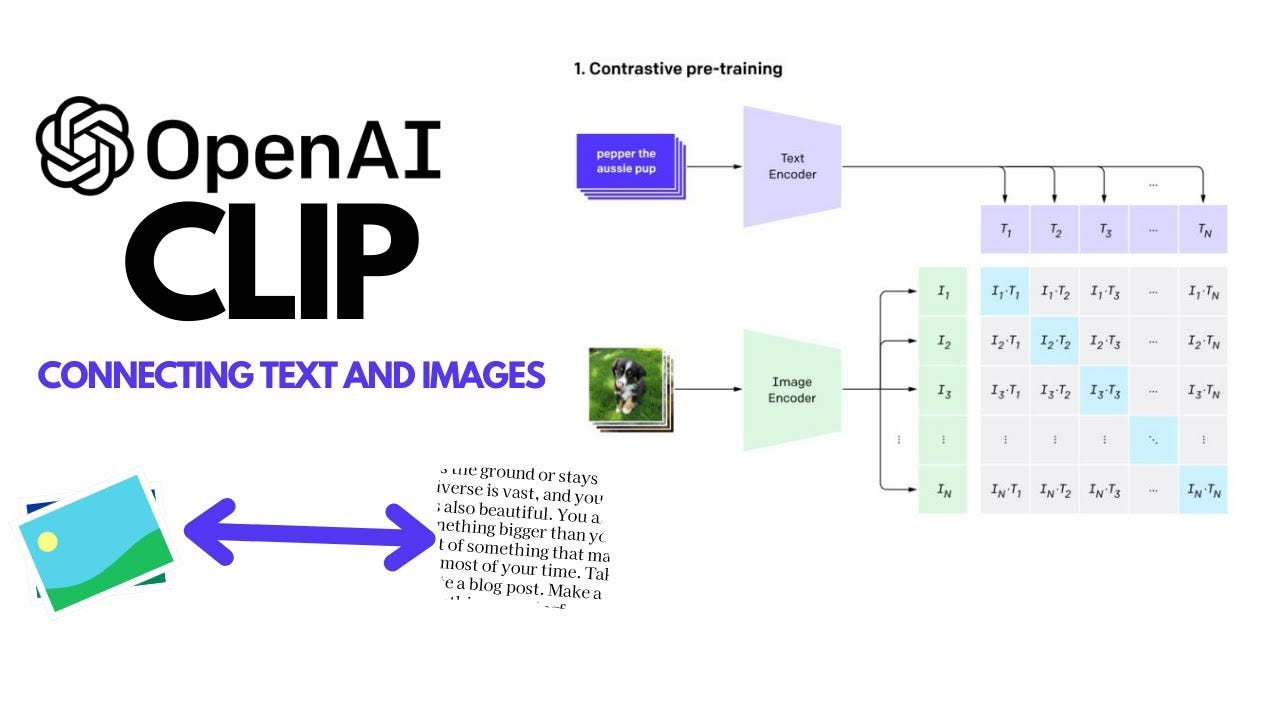
CLIP consists of two main components:
- Image Encoder: A vision model (e.g., Vision Transformer or ResNet) that processes images into feature embeddings.
- Text Encoder: A language model (e.g., Transformer) that converts text descriptions into feature embeddings.
Training Process
- Dataset: CLIP is trained on a massive dataset of image-text pairs (e.g., 400 million pairs scraped from the internet).
- Contrastive Learning:
- For each image-text pair, CLIP learns to maximize the similarity between the correct pair’s embeddings while minimizing similarity with incorrect pairs.
- It uses a contrastive loss function to achieve this, ensuring the model aligns related images and texts in a shared embedding space. - Zero-Shot Capability: After training, CLIP can generalize to new tasks by comparing image embeddings to text embeddings for any given prompt, without further fine-tuning.
Key Features
- Zero-Shot Learning: CLIP can perform tasks like image classification by matching images to text prompts (e.g., “a photo of a dog”) without task-specific training.
- Flexibility: It supports a wide range of vision-language tasks, such as image captioning, visual question answering, and semantic search.
- Robustness: CLIP generalizes well across diverse datasets and tasks, even for out-of-distribution data.
Applications
- Image Classification: Classify images by matching them to text descriptions.
- Text-to-Image Search: Find images based on textual queries.
- Image Generation Guidance: Used in models like DALL·E to guide image generation with text prompts.
- Content Moderation: Detect inappropriate content by analyzing image-text alignment.
Limitations
- Bias: CLIP can inherit biases from its training data, leading to unfair or inaccurate outputs.
- Generalization Gaps: It may struggle with highly specialized domains or abstract concepts.
- Compute Intensive: Training and inference require significant computational resources.
- Text Dependency: Performance relies on the quality and specificity of text prompts.
Why is CLIP Important?
CLIP’s ability to unify vision and language in a single model has revolutionized multimodal AI. Its zero-shot capabilities reduce the need for labeled datasets, making it a versatile tool for real-world applications. It also serves as a foundation for advanced models like DALL·E and Stable Diffusion.
Example Use Case
Suppose you want to classify an image as “cat” or “dog”:
- Input the image to CLIP’s image encoder to get its embedding.
- Input text prompts like “a photo of a cat” and “a photo of a dog” to the text encoder.
- Compare the image embedding to each text embedding. The prompt with the highest similarity score determines the class.
Conclusion
CLIP is a powerful, flexible model that connects images and text through contrastive learning. Its zero-shot capabilities and broad applicability make it a cornerstone of modern multimodal AI, despite challenges like bias and computational demands.