Open-YOLO 3D

Introduction
Open-vocabulary 3D instance segmentation is crucial for applications like robotics and augmented reality, where systems must identify and interact with previously unseen objects. Traditional methods rely heavily on closed-set models and computationally expensive foundation models like SAM and CLIP to project 2D features into 3D space, resulting in slow inference times—ranging from 5 to 10 minutes per scene—which hinders real-time deployment.
To address this challenge, the proposed method, Open-YOLO 3D, introduces a faster and more efficient approach by leveraging 2D object detectors instead of segmentation-heavy models. It uses bounding box predictions from an open-vocabulary 2D detector across multiple RGB frames and combines them with class-agnostic 3D instance masks. By constructing low granularity label maps and projecting the 3D point cloud onto them using camera parameters, Open-YOLO 3D significantly reduces computational costs while maintaining high segmentation accuracy, enabling practical deployment in real-world robotics tasks like material handling and inventory management.
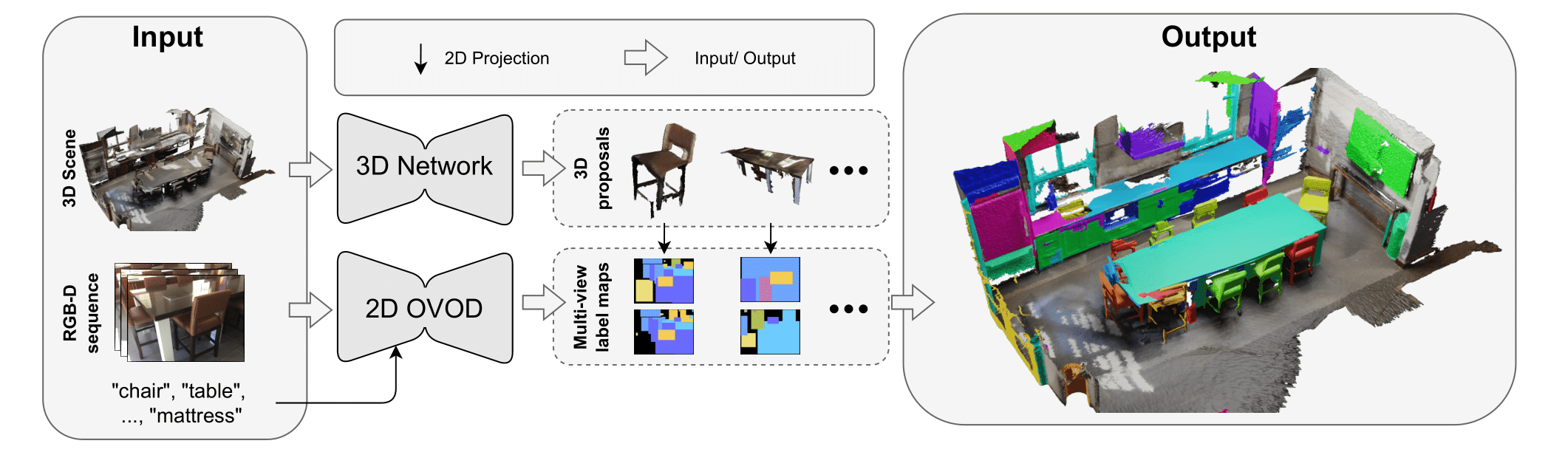
Figure 1: Open-world 3D instance segmentation pipeline
Method
1. Instance Proposal Generation
A 3D instance segmentation network generates binary mask proposals over the input point cloud, with each mask corresponding to a potential object instance.
2. 2D Detection & Label Map Construction
An open-vocabulary 2D object detector predicts bounding boxes and class labels for each RGB frame. These are used to build low-granularity label maps, marking object regions in each image.
3. 3D-to-2D Projection
All 3D points are projected onto the 2D frames using intrinsic and extrinsic camera parameters, creating Nf projections per point across all frames.
4. Accelerated Visibility Computation (VACc)
A fast visibility computation determines where each 3D mask is clearly visible across frames. The top-k most visible projections are selected for each instance.
5. Per-Point Label Assignment
Using (x, y) coordinates from the top-k visible projections, per-point labels are retrieved from the corresponding label maps, filtering out occluded or out-of-frame points.
6. Multi-View Prompt Distribution
Per-point labels from multiple views are aggregated to create a Multi-View Prompt Distribution, allowing assignment of a final prompt ID (class) to each 3D instance mask.
Why It Matters
- Replaces heavy foundation models (SAM, CLIP) with fast 2D object detectors.
- Achieves up to 16× faster inference than prior methods.
- Suitable for real-world robotics scenarios like inventory management and material handling.
- Maintains competitive accuracy while enabling real-time deployment.

Figure 2: OpenYOLO3D with evaluation.
Code
def test(dataset_type, path_to_3d_masks, is_gt):
config = load_yaml(osp.join(f'./pretrained/config_{dataset_type}.yaml'))
path_2_dataset = osp.join('./data', dataset_type)
gt_dir = osp.join('./data', dataset_type, 'ground_truth')
depth_scale = config["openyolo3d"]["depth_scale"]
if dataset_type == "replica":
scene_names = SCENE_NAMES_REPLICA
datatype="point cloud"
elif dataset_type == "scannet200":
scene_names = SCENE_NAMES_SCANNET200
datatype="mesh"
evaluator = InstSegEvaluator(dataset_type)
openyolo3d = OpenYolo3D(f"./pretrained/config_{dataset_type}.yaml")
predictions = {}
for scene_name in tqdm(scene_names):
scene_id = scene_name.replace("scene", "")
processed_file = osp.join(path_2_dataset, scene_name, f"{scene_id}.npy") if dataset_type == "scannet200" else None
prediction = openyolo3d.predict(path_2_scene_data = osp.join(path_2_dataset, scene_name),
depth_scale = depth_scale,
datatype = datatype,
processed_scene = processed_file,
path_to_3d_masks = path_to_3d_masks,
is_gt = is_gt)
predictions.update(prediction)
preds = {}
print("Evaluation ...")
for scene_name in tqdm(scene_names):
preds[scene_name] = {
'pred_masks': predictions[scene_name][0].cpu().numpy(),
'pred_scores': torch.ones_like(predictions[scene_name][2]).cpu().numpy(),
'pred_classes': predictions[scene_name][1].cpu().numpy()}
inst_AP = evaluator.evaluate_full(preds, gt_dir, dataset=dataset_type)
Related Topics
Several approaches have tackled open-vocabulary semantic and instance segmentation by leveraging foundation models like CLIP for unknown class discovery. OpenScene lifts 2D CLIP features into 3D for semantic segmentation, while ConceptGraphs builds open-vocabulary scene graphs for broader tasks like object grounding and navigation. OpenMask3D focuses on 3D instance segmentation using class-agnostic masks combined with SAM and CLIP features, whereas some methods avoid foundation models altogether, relying instead on weak supervision.
- Open-vocabulary semantic segmentation (OVSS): Uses CLIP to align pixel features with text embeddings for zero-shot segmentation.
- AttrSeg: Decomposes class names into attribute phrases, then aggregates them into class representations.
- Open-vocabulary instance segmentation (OVIS): Predicts masks for novel objects using:
- Cross-modal pseudo-labeling with teacher-student models.
- Annotation-free vision-language supervision at box/pixel level.